Hvordan genererer LLM-er tekst?
For å forstå språkmodeller bedre, la oss se på en forenklet forklaring av hvordan de fungerer:
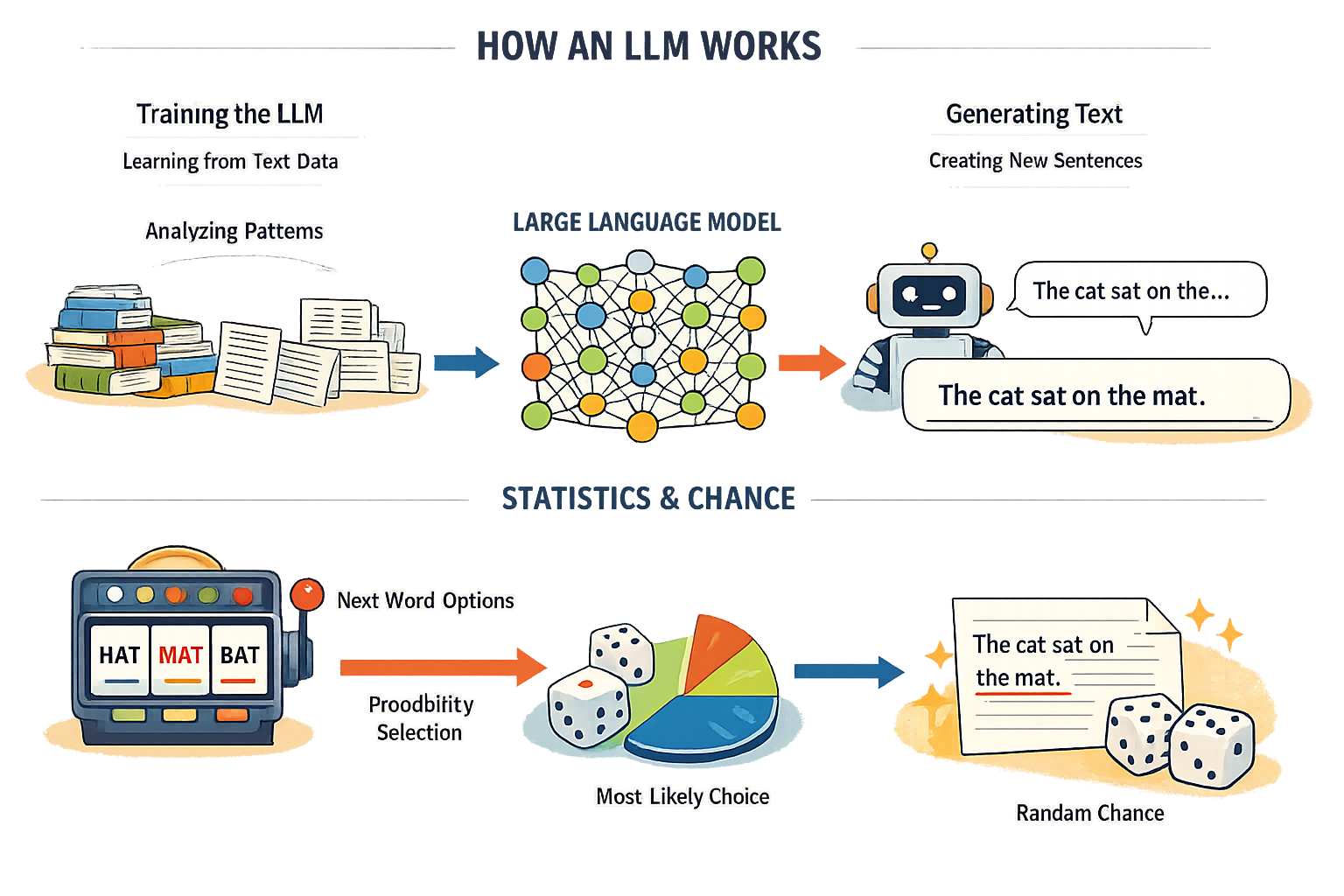
Trening
En språkmodell trenes før den tas i bruk. Modellen lærer ikke mens den brukes. Men noen leverandører av språkmodeller lagrer brukerdata for å trene neste versjon av modellen. Det skal vi komme tilbake til senere, i delen om personvern og data.
Her er en forenklet oppsummering av hva som skjer når modellen trenes:
- Modellen får lese milliarder av ord fra internett, bøker, artikler osv.
- Den lærer hvilke ord som ofte kommer etter hverandre.
- Den lærer mønstre i språk, grammatikk og hvordan setninger bygges opp.
- Den lærer sammenhenger mellom begreper og emner.
Generering
Hva skjer når du stiller et spørsmål:
- Modellen leser spørsmålet eller instruksjonen din.
- Basert på mønstre den har lært, beregner den sannsynlighetene for neste ord i setningen.
- Den trekker et ord, med litt tilfeldighet, og legger det til svaret.
- Den gjentar prosessen for neste ord, og neste ord, osv.
- Modellen stopper når den “mener” svaret er fullstendig.
Fordypning
Tokens og tokenisering
Før språkmodellen kan behandle teksten må den deles opp i mindre biter, kalt tokens. Hvert token gjøres om til et tall, fordi datamaskiner regner på tall. For eksempel kan ordet “er” representeres av tallet 2781 hvert sted i teksten det står. Et token kan være et helt ord, men det kan også være en mindre del av et ord. Denne oppdelingen kalles tokenisering, og programmet som gjør oppdelingen kalles en tokeniserer (tokenizer). På websiden Tiktokenizer kan du skrive inn tekst og se hvordan den deles opp i tokens.
Determinisme/forutsigbarhet
Språkmodeller kan være deterministiske (forutsigbare) hvis de alltid bruker det mest sannsynlige ordet. Men det ville vært ganske kjedelig hvis for eksempel ChatGPT alltid ga samme svar på samme spørsmål. Derfor er det med hensikt lagt inn litt tilfeldighet i hvordan modellene svarer. I stedet for å velge det mest sannsynlige ordet, trekker modellen det neste ordet basert på sannsynlighetene. Det er altså mer sannsynlig å trekke et ord som ofte kommer etter ordene som er generert til nå.
Temperatur og tilfeldighet
Vi kan justere hvor “tilfeldig” eller “kreativ” tekst språkmodellen skal generere. Den mest brukte innstillingen er temperatur. De fleste vanlige tjenester har en standard temperatur som ikke kan justeres, men noen lar deg sette denne etter behov.
Hva er "temperatur"?
Temperaturen kontrollerer hvordan språkmodellen trekker ord fra sannsynlighetsfordelingen. Med høy temperatur øker sannsynligheten for å trekke sjeldne ord.
- Lav temperatur (f.eks. 0.2): Mer forutsigbar, velger de mest sannsynlige ordene.
- Høy temperatur (f.eks. 1.5): Mer kreativ, kan velge mindre sannsynlige ord.
Du kan få dermed ulike svar på samme spørsmål. Noen ganger kan svarene være mer kreative, andre ganger mer “standard”. Det er ingen garanti for at samme spørsmål gir samme svar neste gang.
GPT simulator
Lek med GPT 2 simulatoren for en forenklet model av hvordan LLMer som GPT fungerer!